Introduction
What is the python camproject module?
camproject is a python module that provides functionality for projection from a 3D-scene to the 2D image plane of a camera. It also provides functionality for the reprojection from the 2d image plane to the scene in the 3D world coordinates. It is commonly required in engineering and science applications for georeferencing images.
How it works?
The camera geometry
Lets say, you take a photo of a scene with your camera. Your camera has a lens and a focal plane array (and a lot of other stuff we don’t care about).
camera_example shows how a real world point P(X,Y,Z) is being projected through the center of the lens on to the image pixel coordinates (u,v) of the camera’s focal plane array.
The optical axis pierces the center of the lens and hits the focal plane in the principle point (cx,cy).
The image on the focal plane array is upside down. This leads to the fact that the axes of the image coordinates (u,v) point always in the reverse direction of the world (respectively the camera) coordinates.
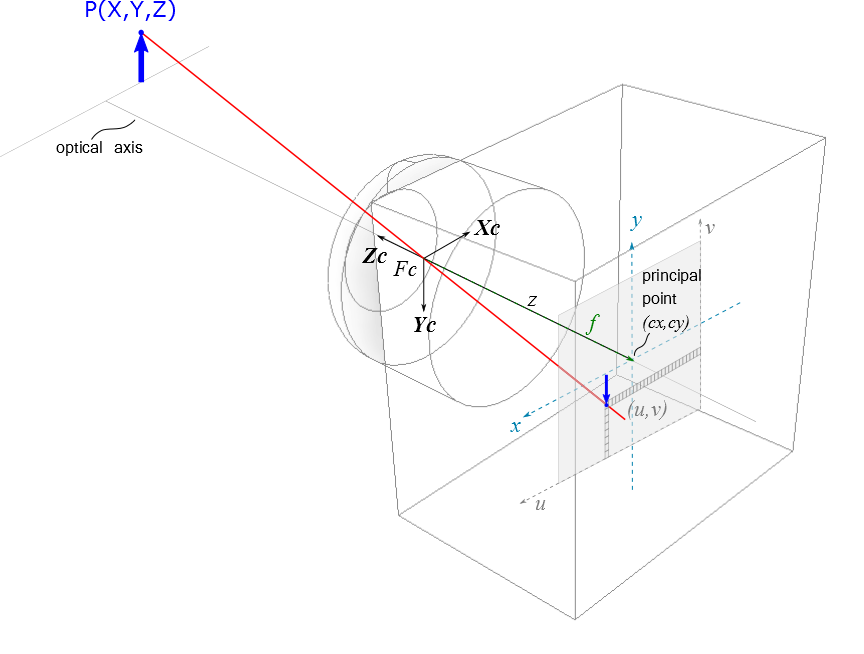
the projection through a camera
To get not that confused with the orientation, the computer vision people always invert the image coordinate system and move the image plane at the same distance (f) in front of the lens. Technically i think it is impossible to realize such a camera, but from the mathematical point of view this leads to the same solution. pinhole_cameramodel shows the simplified model.

simplified camera projection model (this image is based on an illustration from the openCV-Documentation)
Now the axes u and v point in the same direction as Xc and Yc. Zc points into the scene. The center of the lens is always the origin of the camera coordinate system. And we have a right sided coordinate system (left sided are used e.g. in geodetic applications).
Please have a look at the Open CV Camera Calibration Documentation The following documentation extends the OpenCV Docs or writes the same content in different words.
The pinhole camera model
The most simple camera model is the pinhole camera. It consists of a light-tight hollow body with a very small pinhole and a lightsensitive film or an image detector. Due to the fact that it has no lens there exists no geometric distortion or blurring of unfocused objects. .. The pinhole camera can be used as a first order approximation of the mapping from a 3D scene to the image of a real camera.
From the mathematical point of view, the pinhole camera is simply a central projection from 3D to a 2D plane. The projection distance is the focal length of the camera.
With the aid of homogenious coordinates, projective transformations like the central projection are much easier to describe. The projection of a 3D point \(\mathbf{X} \in \mathbb{R}^3\) onto the image plane of a pinhole camera can be described by the equation
The 3D point is expressed by the homogenious vector \(\mathbf{\bar{X}}=[X,Y,Z,W]^T \in \mathbb{P}^3\), while \(X,Y\) and \(Z\) are the same as from our real world \(\mathbf{X} \in \mathbb{R}^3\) and W you can easily set to 1. The resulting image vector \(\mathbf{\bar{x}}\) has the projective coordinates \([x,y,w]^T\). To get the pixel coordinates \([u,v,1]^T\) you have to devide \(\mathbf{\bar{x}}\) by its third component \(w\). \(\mathbf{P}\) is a \(3 \times 4\) projection matrix with
The rotation matrix \(\mathbf{R}\) and the translation vector \(\mathbf{T} \in \mathbb{R}^3\) are the euclidean transformation between the camera and the world coordinate system. We call these parameters the extrinsic camera parameters (or outer orientation). The camera calibration matrix (or inner orientation)
holds the intrinsic parameters of the camera. \(f_x\) and \(f_y\) are the focal distances, with \(f_y = a_r \cdot f_x\). Usually the aspect ratio \(a_r\) is 1. When you now think: how could there be two focal distances for one lens? The answer is: when your detector elements are not quadratic (\(a_r \neq 1\)), then you can use the dectector element size in x or y direction as unit to measure the focal distance. When your focal plane array is sheared you need to set \(s_{xy}\) different to 1. The central point of the camera is at \([c_x,c_y]^T\) (in pixels).
The whole Equation is then:
The image pixel coordinates (u,v) are
Brown’s Camera Model
Until now we have ignored the distortion of the lens, but real camera lenses do have distortion. The brown camera model considers radial and tangential lens distortions.